

Best CSPM for Kubernetes: Why Posture Management Needs Runtime Context
You just connected your Kubernetes clusters to a CSPM tool. Within a few hours, the...


Feb 16, 2022

Though Kubernetes has grown in popularity, it still has a steep learning curve that can make it hard to adopt the technology. Those who can’t get past this initial hurdle are often left behind in the fast-paced field of software development.
This article will introduce YAML files for Kubernetes object configuration. YAML provides a way to declaratively configure your Kubernetes applications, and these declarative files allow you to effectively scale and manage your applications. Without understanding the basics of configuration for Kubernetes objects, it’s easy to fall into the trap of running applications without actually understanding how they work.
It’s important to note that YAML and JSON can be used interchangeably for the configuration of Kubernetes. However, even though YAML is considered more difficult to write in some cases, it’s much more compact. This is a great advantage when considering all the YAML files you would have to manage for large applications.
Overall, YAML tends to be more user-friendly, and the compact nature allows you to group related Kubernetes objects, reducing the number of files required. This is because the design goals of YAML are to increase readability and provide a more complete information model. It can simply be seen as an evolution of JSON.
To get started with YAML for Kubernetes, we’ll review the basic structure types of YAML, which you can see in the table below:
| Key/Field-Value Pair | List | Map |
| app: redis role: replica tier: backend | containers: – name: webserver1 – name: database-server – name: rss-reader | containers: – name: webserver1 image: nginx:1.6 ports: – containerPort:80 – name: database-server image: mysql-3.2 ports: – containerPort:3306 – name: rss-reader image: rss-php-nginx:2.8 ports: – containerPort:86 |
When writing YAML files for Kubernetes, there are four required fields that must be present. APIVersion, Kind, Metadata, and Specifications.
This field refers to the API, which is being used to create the Kubernetes object being defined. Kubernetes provides various APIs that enable you to create different Kubernetes objects. For example, apiVersion: v1 contains many of the core objects.
apiVersion: v1 is usually considered the first stable release by Kubernetes. Another popular APIVersion is apps/v1, which adopts objects from v1 and provides crucial functionality such as deployments and ReplicaSets.
Hence, in our YAML file, defining the APIVersion could be:
apiVersion: v1
kind allows you to specify which type of Kubernetes object you aim to define. The objects that you will specify in this field will be linked to the apiVersion that you specified before since it’s the APIVersion field that enables you to access the different types of objects and their specific definitions. Some of the types of objects that can be defined are pods, services, and DaemonSets.
So, to define a pod object, after specifying the apiVersion, we would specify the kind field as shown below:
apiVersion: v1
kind: pod
After specifying the type of object that’s being defined, the metadata field provides the unique properties for that specific object. This could include the name, uuid, and namespace fields. The values specified for these fields provide us with context for the object, and they can be referred to by other objects. So, this field allows us to specify the identifier properties of the object.
For example, if we are building a spring app, our pod could have the name value shown below:
apiVersion: v1
kind: Pod
metadata:
name: spring-pod
The spec field allows us to define what’s expected from the object that we’re building. It consists of all the key-value pairs specific to defining the operation of the object. Just like the object itself, the specifications of the object depend on the apiVersions specified before. Hence, different APIVersions may include the same object, but the specifications of the object that can be defined will probably differ.
If we continue our example of building the pod object of our spring application, our spec field could resemble what you see below:
apiVersion: v1
kind: Pod
metadata:
name: spring-pod
containers:
– image: armo/springapp:example
spec:
name: spring-app
ports:
– containerPort: 80
protocol: TCP
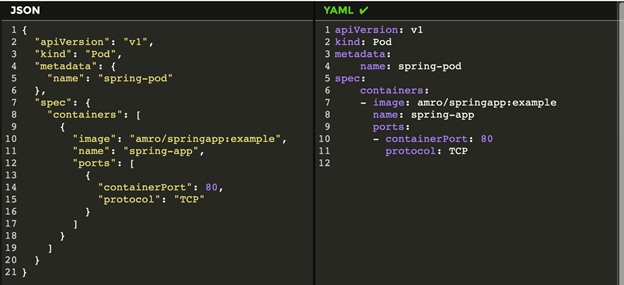
In the final example file above, we’re using the API v1 to create a Pod object, which we have named spring-pod. As per the specifications, the port we will use will be 80 and the image to be used is armo/springapp:example.
The image below compares what the configuration would look like in JSON versus YAML. As you can see, YAML is much more concise and readable.
Now that we’ve built our Kubernetes YAML file, let’s look at some strategies to further accelerate building Kubernetes applications.
As mentioned above, using the YAML field allows you to declaratively manage your Kubernetes applications. These YAML files can be stored in a common directory and may all be applied using kubectl apply -f <directory>.
This is fairly simple. However, as your application evolves and changes are made to the definition of your Kubernetes objects, you’ll have to consider which version and which change is currently deployed. This is because, without versioning, you may not be able to roll back to previous images, which may have been more stable than the new, active images.
There are several ways to approach YAML versioning, and they range in complexity and ease of management. This could involve using simple tags in your YAML along with the manual kubectl commands or could entail employing special tools such as Helm. Going into detail about each of these methods is out of the scope of this article, but it’s worth mentioning that versioning is an important practice.
Throughout the lifecycle of your application, you may need to support its function by leveraging confidential data. This could include passwords, user information, or even credit card details.
You can put this data directly in your YAML files as variables while you define your Kubernetes objects. However, this can lead to major security lapses, and it increases the possibility of this data falling into the wrong hands. Hence, it’s recommended to use the Secrets object provided with Kubernetes along with secrets management tools.
When leveraging the Secrets object, the pod must reference the Secret. So, this is where we use the metadata field. The pod will use the Secret name field, where the name of a Secret object will be a valid DNS subdomain name.
An example of the defined Secrets object can be seen below:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
Be sure to note the Secret type. In the example above, we’ve specified the Secrets type as Opaque. This is the default type of the Secret object. Another Secret type is kubernetes.io/service-account-token, which is used to store service account identifier tokens.
Additional, detailed information on how to manage secrets in Kubernetes can be found in ARMO’s resources.
YAML Templating aims to reduce the number of YAML files we have to write and manage by reusing them across your Kubernetes application. For example, let’s consider the pod definition below:
apiVersion: v1
kind: Pod
metadata:
name: spring-pod
spec:
containers:
– image: armo/springapp:example
name: spring-app
env:
– name: eu-west-1
value: postgres://db_url:5432
This pod will be in the eu-west-1 region. However, if we want to deploy to us-west-1 for our U.S.-based customers, we would have to write a new YAML file since we are using hardcoded values.
The solution to this issue is YAML templating, which allows us to reuse the YAML file with different values. There are several approaches to YAML templating, but the most basic method is to search and replace where we leverage placeholders for the values in the YAML file.
So, using the original example, we would have a placeholder value as is seen under the env field:
apiVersion: v1
kind: Pod
metadata:
name: spring-pod
spec:
containers:
– image: armo/springapp:example
name: spring-app
env:
– name: ENV
value: %DEPLOYMENT_ENV%
By leveraging sed in bash, we can search and replace these values before the YAML files are processed. However, this is the most basic and least convenient method, because you would have to perform the hard coding of placeholders manually.
A more convenient approach is to leverage a tool like Helm to build and manage your templates.
Thanks to the way YAML is structured and its design goals, it’s the best solution for Kubernetes configuration. The increased readability and concise structure allow you to scale your Kubernetes configurations without getting lost in heaps of configuration files.
Furthermore, by understanding how to build Kubernetes applications in a declarative fashion, we can also understand the mechanics of how and why our Kubernetes applications run. Thinking about advanced functionality like YAML templating can help ease the process of defining and building our Kubernetes applications.

You just connected your Kubernetes clusters to a CSPM tool. Within a few hours, the...

AI Agent Sandboxing Has a Definition Problem You’re in a Slack thread at 9 AM...


Every cloud security vendor now has an AI-SPM dashboard. Strip away the branding, though, and...




