WTF are MCP servers and why do we need them
These days it seems everyone is obsessed with MCP servers, me included. After studying the...


Dec 27, 2021

Five months ago, we decided to release a posture management solution for K8s and make it open source for everyone to enjoy it. Today, I can proudly say that it is more successful than I ever expected it to be when we launched it – we have hundreds of registered users, thousands of runs each day, and almost 5K git stars, and it’s growing every day
Kubescape, which started as a tool that scans K8s clusters, YAML files, and HELM Charts for misconfiguration, now offers more capabilities: It scans worker nodes and control nodes (API server, managed and unmanaged). It offers image scanning and RBAC visualization.
The feedback I get from users is AMAZING and we keep developing and improving it based on end-users requirements!
Still, there is one feedback I get that made me write this blog; many users claim that they don’t have time to work with Kubescape outputs. In most organizations, DevOps teams have such a big backlog that they run Kubescape to help them find security-related issues and misconfiguration, but they are overwhelmed with the number of issues that they were not aware of. This is the reason that brought me to share what we do today and what we will do in the future to help DevOps get another member in your DevOps team – Kubescape.
The way I see users usually using Kubescape is as follows:
The real challenge is step #2 above – how to set the baseline and make sure that these issues do not occur again. In the next section, I am going to share the capabilities we developed to help you with this task.
Failed resources
Upon scanning the cluster for risk (the exact chosen framework does not matter). You get a detailed report with the name of the control, risk number, the status of the control (failed or passed), remediation instructions, and the number of resources that failed. You can see from the failed resource count if the number of failed resources did not change from the scan you did before, increased or decreased. This provides a very powerful capability to quickly understand what changed since the last scan.
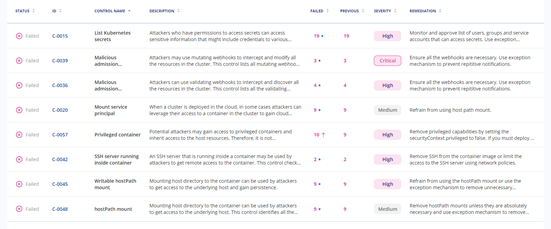
Once you click on the failed resources number, a pop-up appears that shows the detailed list of the resources that failed.
In this view we provide you with the following capabilities:
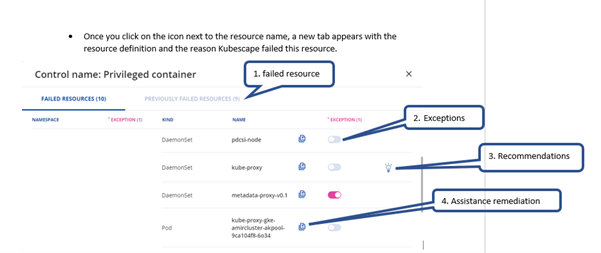
You can copy the object or download it as a file, fix it and apply it to your cluster.
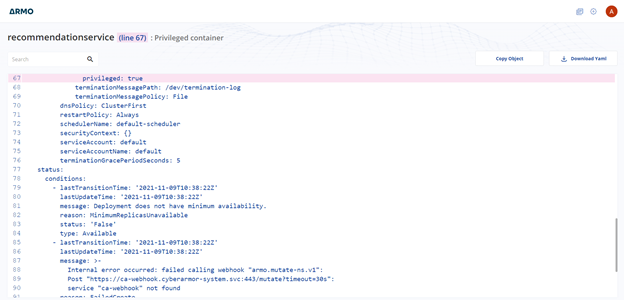


Using the above capabilities, you should be able to set the threshold of your cluster easily and from that point on, just focus on changes.
You can monitor these changes in the risk score change (the higher it is, the riskier it is) and the graph.
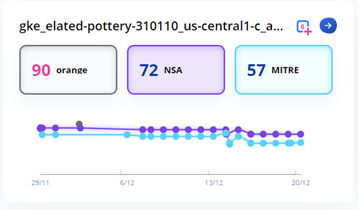
Still, we thought that we can help our users a lot more.
Kubescape is going to support additional capabilities to help you accelerate your work.
In the next versions, Kubescape is going to give you an option to define per control if you want it to be: monitored, enforced, or remediated. This setting will be per cluster and/or namespace.
The last feature we are going to develop is Contextual Priority. We know that not all alerts are created equally. While some have a critical severity, it might be that network connectivity is needed to be able to exploit it. But your application is not connected to any network resource hence you can postpone/deprioritize it. Understanding it will help to point your efforts to the places where your organization benefits the most.
We understand that running a posture product might be scary as you hardly handle all the tasks you have today and don’t want to be buried with additional tasks. Not knowing is sometimes better, but it comes with a risk (that Kubescape scores).
We designed Kubescape to help you by:
1) Set a healthy baseline:
2) Identify drifts – see what changed since the last scan
3) Make sure mistakes do not happen – by setting a policy that enforces these controls and/or remediates failed controls
And lastly, we help you point your efforts in the right directions by giving you a short “to-do” list that is based on the right context.

These days it seems everyone is obsessed with MCP servers, me included. After studying the...

Kubernetes v1.34 is coming soon, and it brings a rich batch of security upgrades –...

At ARMO, our mission is to make Kubernetes security more accessible, actionable, and effective. That’s...



