Software Supply Chain Security: A Detailed Explanation
Software supply chain attacks cost businesses $45.8 billion globally in 2023 alone, and is projected...


Apr 17, 2024

The shift to cloud has meant an explosion in cloud security-related acronyms – so many that it can be difficult to know what you currently have versus what’s missing or available. First, we bought CSPMs (Cloud Security Posture Management), then CWPPs (Cloud Workload Protection Platforms), then CNAPPs (Cloud Native Application Protection Platforms), then CDRs (Cloud Detection & Response), and now KDRs (Kubernetes Detection Response). Along the way, EDR (Endpoint Detection Response) providers pretended they could do it all, but provided broken agents that barely worked in these new environments.
In this article, I argue that most existing runtime solutions are insufficient to say that they provide “Cloud Detection Response” capabilities. They tend to lack key components to make responding to cloud incidents possible, either by lacking the visibility they claim to offer (CSPM) or by lacking the relevant cloud context to make an alert understandable (EDR). Instead, a new conception of runtime detection response is required, one that integrates more holistically across clouds.
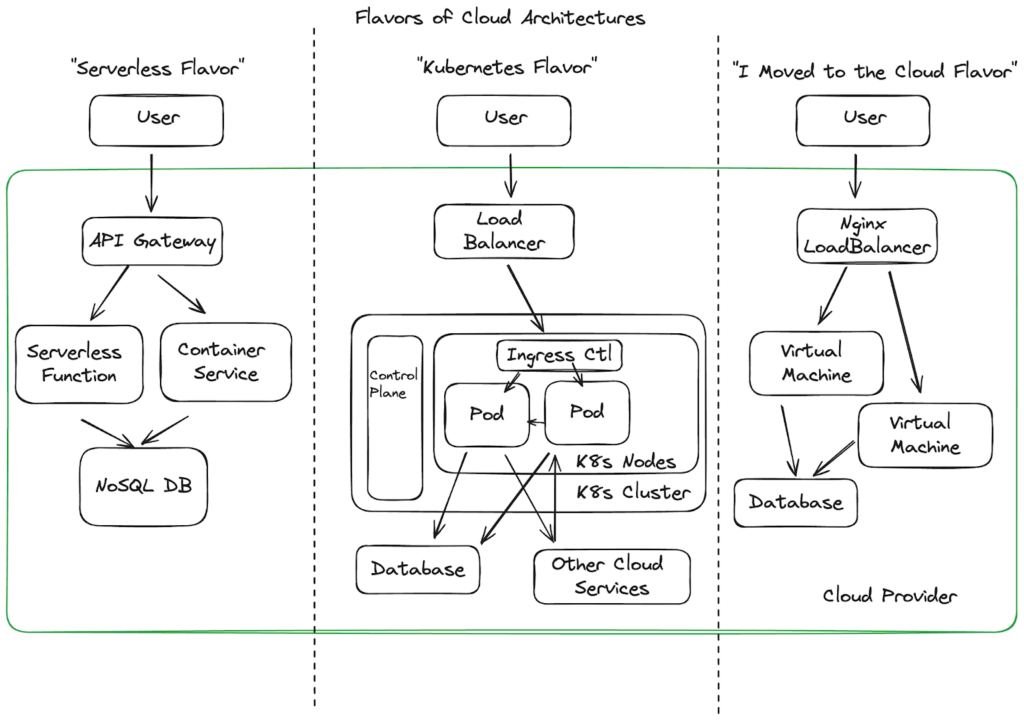
The conversation of “what’s the best runtime protection for my cloud workloads” quickly deteriorates because there are so many ways to build applications in the cloud. Some of those, that shifted on prem architectures into the cloud, don’t benefit much from next generation detection response providers. They’re still running their windows servers, nginx load balancers, or JVMs, but now they’re paying Amazon to host them.
Alternatively, most companies are either building new projects, side projects, or porting their legacy ones into Kubernetes architectures. Another common pattern is for an app to start with a serverless architecture, and then shift into Kubernetes as serverless demands become either too unwieldy or start to lack customization needed by larger teams.
Ironically, these architectures become more difficult to secure as they become more cloud-native due to the more transitive nature of the workloads. In this section, we’ll break down the different technologies that have been used to protect these types of infrastructure.
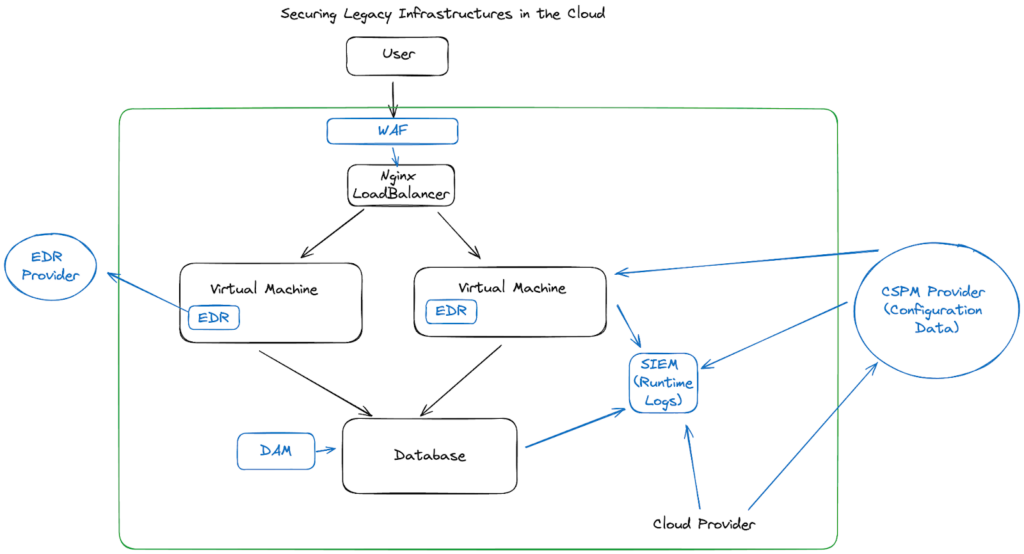
In the above diagram, we see the standard toolbelt of legacy security. EDR ran as an agent on the virtual machines, with most of them having strong sets of Windows-based rules, and very weak Linux protections. This was a time where I saw audit reports claim that Linux machines were low risk because there were no exploits against them (ha).
The key technologies here are:
As teams began to triage alerts from their CSPM, like “this EC2 instance has a vulnerability”, they quickly realized that these alerts were best actioned by developers, not by security teams. Security operations were quickly frustrated with the noise associated with cloud logs, where every action creates a log with endless possible correlations.
It’s from this mindset that CDR emerged – I think of it as CSPM but focused at more runtime-y correlations. To be frank, I’m shocked at the valuation of some of these tools, because they provide no greater visibility than CSPM. In other words, how can you say you’re doing cloud detection and response if you still need a separate agent to protect your workloads!?
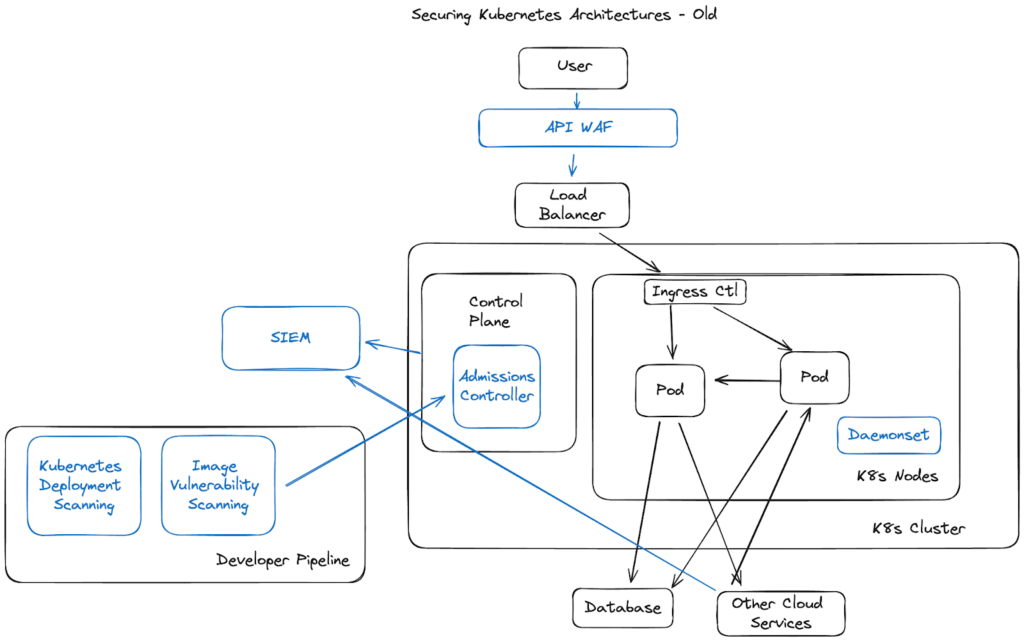
Because Kubernetes workloads have fundamentally different architectures, the early days of cloud security were full of experimentation. Unfortunately, the attitude that took hold was similar to what people thought of Linux workloads – exploits are too hard, too uncommon, and the configuration can be so secure that runtime inside the Kubernetes cluster isn’t needed.
A lot of focus at this time was scanning deployments for misconfigurations and images for vulnerabilities. The thought was that if we can limit what pods have access to, and remove all of the vulnerabilities from them, then an attacker won’t be able to get in, and even if they do, they won’t be able to do any damage. Unfortunately, reality quickly set in.
Early Kubernetes “agents”, that were a lot of times just existing linux agents slammed onto the underlying nodes, didn’t provide basic context for what their alerts were seeing. For example, tell me what container had an issue based on the below alerts:

Many vendor agents were useless in these new environments, because their alerts still just used linux processes and file paths, which would point to a bunch of meaningless strings that represented specific containers.
On the other side, developers were slammed with vulnerabilities they couldn’t fix. Vulnerabilities poured in from every open-source package and image, almost none of which were actually exploitable or even running in their environment. At this point, most of the big platform players were too busy acquiring acronyms to add to their sales deck to notice that their existing scanning was unusable in these environments.
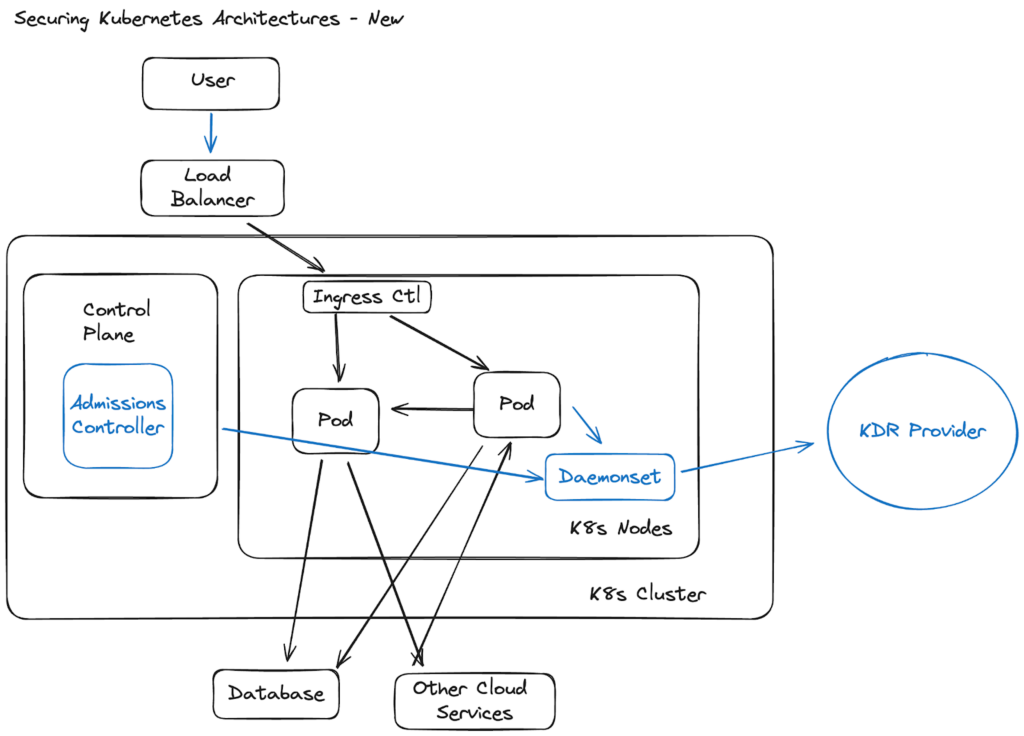
The nature of Linux and Kubernetes protection changed drastically with the introduction of eBPF. eBPF is a Linux kernel technology that has been developed and maintained by the Linux community. Its adoption is driven by various use cases, such as networking, observability, and security. The transition of eBPF into a tool in the Kubernetes tool belt is a natural progression, as it offers significant benefits in areas such as networking, observability, and security for containerized workloads. In this case, we are talking about using eBPF to inform KDR, by observing micro-interactions happening within these workloads, creating a baseline and evaluating it against pre-set rules to detect anomalous behavior.
While a lot of vendors stalled out on their Kubernetes disciplines, content with things like admissions controllers for vulnerable images, some continued and have fully realized the protection potential available from within the cluster with eBPF. Within the cluster, these newer breed of agents differentiate from the old ones with the following capabilities:
| Old Tool and Capability | New Tool and Capability |
| Image Registry Vulnerability Scanning | In-cluster image scanning with runtime context and drift detection |
| IaC Scanning basic Terraform, with a static view of pod behavior and deployments | Runtime pod behavior analysis with drift detection from configured rules |
| Sending Control Plane Logs to a SIEM or CDR | Correlating control plane logs with container activity to give a complete picture of actions taken within a pod |
| EDR alerting on Linux suspicious activities | Giving full pod and container context to alerts as they come in, with runtime blocking (powered by eBPF) |
| Lack of east / west network visibility across pods | Pod to pod network visibility and control |
| Define policies in advance to limit container actions | Build policies based on runtime behavior in lower environments |
The attack I always think of when assessing runtime protection tools is the following:
| Attack | Needed Detection or Prevention Tool |
| Remote Code Execution | RASP, SAST, WAF |
| Stolen Credentials | MDM, SIEM, Control Plane Monitoring |
| Scraping Credentials from a pod | Container Runtime Security |
| Spinning up a new privileged pod | Misconfiguration scanning with CSPM or IaC |
| Attacker uses that pod for access to cloud resources | Container Runtime Security, CDR, CNAPP |
| Attacker Exfiltrates Sensitive Data | CDR, DAM |
Here’s what would detect all of these:
As you can see, while CNAPP promises to be the all-in-one protection platform, to stop a real Kubernetes attack you need 3-8 different tools, including the CNAPP. That’s why I view KDR as the heartbeat of CNAPP – securing the cluster is securing the cloud. A CNAPP without complete cluster visibility utterly fails to protect the architecture most common to the cloud.
Here are some conclusions:
Most companies I talk to fail to adopt this category of solution because they’re afraid of the learning curve to install the agent; however, the only alternative is for teams to bury their heads in the sand and watch as their CNAPP alerts pile up without preventing anything. I’ve said it elsewhere and I’ll say it again, instead of avoiding a tool because it has a Kubernetes agent, you should buy it because it has one. You need your team to learn it, and deploying a lightweight daemonset is the best way to get started (like ARMO’s Cloud Detection & Response!).

Software supply chain attacks cost businesses $45.8 billion globally in 2023 alone, and is projected...

Imagine this situation: you recently updated one of your infrastructure software components. A few weeks...


It is becoming increasingly important for organizations to manage Kubernetes security costs as they deploy,...



