What it takes to do Cloud Detection & Response
A guest post by James Berthoty the founder of Latio Tech. The shift to cloud...


Apr 8, 2024

Seccomp, short for Secure Computing Mode, is a noteworthy tool offered by the Linux kernel. It is a powerful mechanism to restrict or log the system calls that a process makes. Operating within the kernel, seccomp allows administrators and developers to define fine-grained policies for system call execution, enhancing the overall security posture of applications and the underlying system. By filtering and limiting the system calls accessible to a process, seccomp aids in minimizing the potential impact of vulnerabilities and decreases the attack surface. This makes it a key element in creating robust and secure Linux environments.
In this blog, we will explore the internals of seccomp, including its architecture, key concepts, and practical applications. We’ll illustrate how this security feature contributes to the comprehensive, defense-in-depth strategy for systems based on Linux. This is part one of a two part blog post.
Please note that in this blog series we will be giving examples of Linux kernel code and that the code snippets may not age well. So, keep in mind that the code snippets below refer to x86_64 architecture with Linux kernel version 6.7.1.
In addition, detailing every single function and feature of seccomp will extend the length of the blog significantly. As a result, I have chosen to focus on the parts that I view as key to gaining a deep understanding of seccomp.
The idea behind seccomp is quite simple, a process can define seccomp in one of two modes: strict or filter.
Strict mode limits the process to only four system calls (read, write, _exit, sigreturn). Any other system calls result in the termination of the calling thread, or termination of the entire process with the SIGKILL signal when there is only one thread.
Unlike strict mode, filter mode offers more flexibility and power to seccomp. In filter mode one can create a Berkeley Packet Filter (BPF) program, similar to socket filters. However, the data operated on applies to the system call being executed, including the system call number and its respective arguments. This allows for expressive filtering of system calls using a filter program language with a long history of being exposed to userspace and a straightforward data set. The straightforward data set further simplifies the filtering process.
In order to set a seccomp we can use the prctl system call. It allows us to manipulate various aspects of the behavior of the calling thread or process. Below is an example of seccomp set in strict mode:
#include <stdio.h> #include <stdlib.h> #include <sys/prctl.h> #include <linux/seccomp.h> #include <unistd.h> #include <fcntl.h> #include <errno.h> int main() { // Enable seccomp in strict mode. prctl(PR_SET_SECCOMP, SECCOMP_MODE_STRICT); // Try to open a file. int fd = open("example.txt", O_RDONLY); // We shouldn't get to here. ... }
Once the program or more specifically the task (process) tries to execute the open system call, it will receive a SIGKILL signal. This is because it is not part of the four allowed system calls in strict mode.
Now, let’s define a BPF seccomp filter:
#include <errno.h> #include <linux/audit.h> #include <linux/bpf.h> #include <linux/filter.h> #include <linux/seccomp.h> #include <linux/unistd.h> #include <stddef.h> #include <stdio.h> #include <sys/prctl.h> #include <unistd.h> static int install_filter(int nr, int arch, int error) { struct sock_filter filter[] = { BPF_STMT(BPF_LD + BPF_W + BPF_ABS, (offsetof(struct seccomp_data, arch))), BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K, arch, 0, 3), BPF_STMT(BPF_LD + BPF_W + BPF_ABS, (offsetof(struct seccomp_data, nr))), BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K, nr, 0, 1), BPF_STMT(BPF_RET + BPF_K, SECCOMP_RET_ERRNO | (error & SECCOMP_RET_DATA)), BPF_STMT(BPF_RET + BPF_K, SECCOMP_RET_ALLOW), }; struct sock_fprog prog = { .len = (unsigned short)(sizeof(filter) / sizeof(filter[0])), .filter = filter, }; if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) { perror("prctl(NO_NEW_PRIVS)"); return 1; } if (prctl(PR_SET_SECCOMP, 2, &prog)) { perror("prctl(PR_SET_SECCOMP)"); return 1; } return 0; } int main() { printf("hey there!\n"); install_filter(__NR_write, AUDIT_ARCH_X86_64, EPERM); printf("something's gonna happen!!\n"); printf("it will not definitely print this here\n"); return 0; }
This filter is taken from the following github gist. The filter applies a policy where it denies all the write system calls. In case of a write system call it will exit with the error EPERM.
As we can see in the strace output attached in the gist:
write(1, "hey there!\n", 11hey there! ) = 11 prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0) = 0 prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, {len=6, filter=0x7ffe3fd635b0}) = 0 write(1, "something's gonna happen!!\n", 27) = -1 EPERM (Operation not permitted) write(1, "it will not definitely print thi"..., 39) = -1 EPERM (Operation not permitted) exit_group(0) = ? +++ exited with 0 +++
In order to compile the above program, we can use gcc:
gcc seccomp-program -o seccomp-program.c
You are probably asking yourself, how is seccomp even implemented from the operating system perspective? Well, the answer lies in the task_struct. Let’s dive into some kernel code in order to really understand what is going on.
If we take a look at the task_struct we can see a field of type struct seccomp, this field contains the seccomp related data of the task. Remember seccomp policies are defined per task. The fact that seccomp is defined per task, raises another question, what happens when a new thread (aka task) starts? Does it inherit the parent’s seccomp settings? Keep that question in mind, we will answer it later in this blog.
struct task_struct { ... struct seccomp seccomp; ... }
The seccomp struct is constructed as follows:
struct seccomp { int mode; atomic_t filter_count; struct seccomp_filter *filter; };
The fields are pretty much self explanatory. We have the mode which indicates the seccomp mode (strict vs filter). In addition we have an atomic_t filter count which holds the number of filters we have, and lastly, we have the seccomp_filter field which is a pointer to the struct that contains our filters.
The seccomp_filter struct is interesting because it highlights that filters can be shared between different tasks (sibling threads), similar to namespaces.
struct seccomp_filter { refcount_t refs; refcount_t users; bool log; bool wait_killable_recv; struct action_cache cache; struct seccomp_filter *prev; struct bpf_prog *prog; struct notification *notif; struct mutex notify_lock; wait_queue_head_t wqh; };
There are several interesting fields here. Let’s examine them.
The first one is the bpf_prog field which contains a pointer to the BPF program that is actually the filter’s logic.
The second one is the notification field which we will discuss in more detail in the second part of this blog series. And, of course we see a pointer to the previous filter, if one exists. The refs and users fields indicate how many tasks are using this filter so the kernel will know when it can safely free the memory holding it
Now that we understand the structures involved in seccomp let’s take a look at how they are used by the kernel.
As I mentioned before, to set up seccomp we can use the prctl system call. We can also use the seccomp system call, both are defined in the “kernel/seccomp.c” file.
/** * prctl_set_seccomp: configures current->seccomp.mode * @seccomp_mode: requested mode to use * @filter: optional struct sock_fprog for use with SECCOMP_MODE_FILTER * * Returns 0 on success or -EINVAL on failure. */ long prctl_set_seccomp(unsigned long seccomp_mode, void __user *filter) { unsigned int op; void __user *uargs; switch (seccomp_mode) { case SECCOMP_MODE_STRICT: op = SECCOMP_SET_MODE_STRICT; /* * Setting strict mode through prctl always ignored filter, * so make sure it is always NULL here to pass the internal * check in do_seccomp(). */ uargs = NULL; break; case SECCOMP_MODE_FILTER: op = SECCOMP_SET_MODE_FILTER; uargs = filter; break; default: return -EINVAL; } /* prctl interface doesn't have flags, so they are always zero. */ return do_seccomp(op, 0, uargs); }
AND
SYSCALL_DEFINE3(seccomp, unsigned int, op, unsigned int, flags, void __user *, uargs) { return do_seccomp(op, flags, uargs); }
Both ways lead to the function “do_seccomp”. This function receives 3 arguments, the operation (strict vs filter), some flags and a user mode pointer to the filter BPF. Notice that in case of strict mode the pointer is set to NULL because no filter is applied.
static long do_seccomp(unsigned int op, unsigned int flags, void __user *uargs) { switch (op) { case SECCOMP_SET_MODE_STRICT: if (flags != 0 || uargs != NULL) return -EINVAL; return seccomp_set_mode_strict(); case SECCOMP_SET_MODE_FILTER: return seccomp_set_mode_filter(flags, uargs); case SECCOMP_GET_ACTION_AVAIL: if (flags != 0) return -EINVAL; return seccomp_get_action_avail(uargs); case SECCOMP_GET_NOTIF_SIZES: if (flags != 0) return -EINVAL; return seccomp_get_notif_sizes(uargs); default: return -EINVAL; } }
This function in turn, executes additional validations, like ensuring that if a mode was already set, it can’t be changed. Eventually the functions “seccomp_set_mode_strict” and “seccomp_set_mode_filter” are called depending on the requested mode. In both of the functions there is a call to “seccomp_assign_mode” which actually sets the task->seccomp.mode field to the correct mode.
static inline void seccomp_assign_mode(struct task_struct *task, unsigned long seccomp_mode, unsigned long flags) { assert_spin_locked(&task->sighand->siglock); task->seccomp.mode = seccomp_mode; /* * Make sure SYSCALL_WORK_SECCOMP cannot be set before the mode (and * filter) is set. */ smp_mb__before_atomic(); /* Assume default seccomp processes want spec flaw mitigation. */ if ((flags & SECCOMP_FILTER_FLAG_SPEC_ALLOW) == 0) arch_seccomp_spec_mitigate(task); set_task_syscall_work(task, SECCOMP); }
In addition to setting the mode, the function does one more important thing, It calls “set_task_syscall_work” with the respective task and an argument of SECCOMP. This will cause a change in the “thread_info” struct in the syscall_work field. It will indicate that when the thread dispatches an incoming syscall it will first check the seccomp policy to see if it may actually perform the system call. Please note that this specific syscall_work implementation is characteristic to some architectures such as x86. In other architectures, such as arm64, for example, a flag _TIF_SECCOMP is set instead.
In the case of filter mode we also need to set the filter and copy the BPF program from user memory to kernel memory in order to prevent tampering of the data and TOCTOU attacks.
static long seccomp_set_mode_filter(unsigned int flags, const char __user *filter) { ... /* Prepare the new filter before holding any locks. */ prepared = seccomp_prepare_user_filter(filter); if (IS_ERR(prepared)) return PTR_ERR(prepared); ... ret = seccomp_attach_filter(flags, prepared); if (ret) goto out; /* Do not free the successfully attached filter. */ prepared = NULL; seccomp_assign_mode(current, seccomp_mode, flags); }
In the snippet above, we can see the call to “seccomp_prepare_user_filter” and the call to “seccomp_assign_mode”.
In the function “seccomp_prepare_user_filter” we can see a call to “copy_from_user” which copies the BPF program to kernel memory space and a call to “seccomp_prepare_filter”.
/** * seccomp_prepare_filter: Prepares a seccomp filter for use. * @fprog: BPF program to install * * Returns filter on success or an ERR_PTR on failure. */ static struct seccomp_filter *seccomp_prepare_filter(struct sock_fprog *fprog) { struct seccomp_filter *sfilter; int ret; const bool save_orig = #if defined(CONFIG_CHECKPOINT_RESTORE) || defined(SECCOMP_ARCH_NATIVE) true; #else false; #endif if (fprog->len == 0 || fprog->len > BPF_MAXINSNS) return ERR_PTR(-EINVAL); BUG_ON(INT_MAX / fprog->len < sizeof(struct sock_filter)); /* * Installing a seccomp filter requires that the task has * CAP_SYS_ADMIN in its namespace or be running with no_new_privs. * This avoids scenarios where unprivileged tasks can affect the * behavior of privileged children. */ if (!task_no_new_privs(current) && !ns_capable_noaudit(current_user_ns(), CAP_SYS_ADMIN)) return ERR_PTR(-EACCES); /* Allocate a new seccomp_filter */ sfilter = kzalloc(sizeof(*sfilter), GFP_KERNEL | __GFP_NOWARN); if (!sfilter) return ERR_PTR(-ENOMEM); mutex_init(&sfilter->notify_lock); ret = bpf_prog_create_from_user(&sfilter->prog, fprog, seccomp_check_filter, save_orig); if (ret < 0) { kfree(sfilter); return ERR_PTR(ret); } refcount_set(&sfilter->refs, 1); refcount_set(&sfilter->users, 1); init_waitqueue_head(&sfilter->wqh); return sfilter; }
This function does a number of things. First, it validates that we have sufficient permissions to install the seccomp filter, a “CAP_SYS_ADMIN” capability is required and “no_new_privs” bit to be set.
prctl(PR_SET_NO_NEW_PRIVS, 1);
This will disable the addition of any privileges to the process and will also prevent the process from accessing a different user ID by running setuid or setgid programs.
Secondly, it creates a new seccomp filter and ultimately raises the reference count of both fields, refs and users to 1.
Let’s recap what we have achieved at this point. We are in a state where we enabled seccomp and the task_struct is initialized with the needed seccomp data, mode and filters.
The last thing we need to understand is the journey of a syscall to see where exactly seccomp kicks in.
So, before jumping into the syscall journey, let’s rewind to the question I mentioned above, what happens when a new thread (aka task) starts? Does it inherit the parent’s seccomp settings?
The answer is yes, new threads inherit the seccomp settings from the parent, which is an expected behavior. What about threads that were already running? In this case you can pass a flag when applying seccomp that will sync all the other threads as well SECCOMP_FILTER_FLAG_TSYNC.
Covering the way system calls work in Linux can be a blog series in its own right. Nevertheless, to see where seccomp kicks in, let’s dive into parts of the syscall journey and find what we need.
When a syscall is made ultimately the “do_syscall_64” function is called, which in turn, triggers a call to “__syscall_enter_from_user_work” .
static __always_inline long __syscall_enter_from_user_work(struct pt_regs *regs, long syscall) { unsigned long work = READ_ONCE(current_thread_info()->syscall_work); if (work & SYSCALL_WORK_ENTER) syscall = syscall_trace_enter(regs, syscall, work); return syscall; }
This function checks if there is “work” to be done. We know there is, because if you recall, the field syscall_work was set when we initialized seccomp. Next we call “syscall_trace_enter”.
static long syscall_trace_enter(struct pt_regs *regs, long syscall, unsigned long work) { long ret = 0; /* * Handle Syscall User Dispatch. This must comes first, since * the ABI here can be something that doesn't make sense for * other syscall_work features. */ if (work & SYSCALL_WORK_SYSCALL_USER_DISPATCH) { if (syscall_user_dispatch(regs)) return -1L; } /* Handle ptrace */ if (work & (SYSCALL_WORK_SYSCALL_TRACE | SYSCALL_WORK_SYSCALL_EMU)) { ret = ptrace_report_syscall_entry(regs); if (ret || (work & SYSCALL_WORK_SYSCALL_EMU)) return -1L; } /* Do seccomp after ptrace, to catch any tracer changes. */ if (work & SYSCALL_WORK_SECCOMP) { ret = __secure_computing(NULL); if (ret == -1L) return ret; } /* Either of the above might have changed the syscall number */ syscall = syscall_get_nr(current, regs); if (unlikely(work & SYSCALL_WORK_SYSCALL_TRACEPOINT)) trace_sys_enter(regs, syscall); syscall_enter_audit(regs, syscall); return ret ? : syscall; }
This function checks the work to be done, in addition to the seccomp work. If SYSCALL_WORK_SECCOMP is part of the work to be done then there is a call to “__secure_computing”.
int __secure_computing(const struct seccomp_data *sd) { int mode = current->seccomp.mode; int this_syscall; if (IS_ENABLED(CONFIG_CHECKPOINT_RESTORE) && unlikely(current->ptrace & PT_SUSPEND_SECCOMP)) return 0; this_syscall = sd ? sd->nr : syscall_get_nr(current, current_pt_regs()); switch (mode) { case SECCOMP_MODE_STRICT: __secure_computing_strict(this_syscall); /* may call do_exit */ return 0; case SECCOMP_MODE_FILTER: return __seccomp_filter(this_syscall, sd, false); /* Surviving SECCOMP_RET_KILL_* must be proactively impossible. */ case SECCOMP_MODE_DEAD: WARN_ON_ONCE(1); do_exit(SIGKILL); return -1; default: BUG(); } }
In the code snippet above we can see that we check the seccomp mode and initiate all the seccomp processes that we covered earlier in the blog. In the case of filter mode, “__seccomp_filter” will call “seccomp_run_filters” which will run all the applied filters. In the case of strict mode, it will check if syscall is in the allowed syscall list as mentioned above.
At this point we have a pretty good understanding of what happens when we initiate seccomp and how the kernel uses it. Awesome!
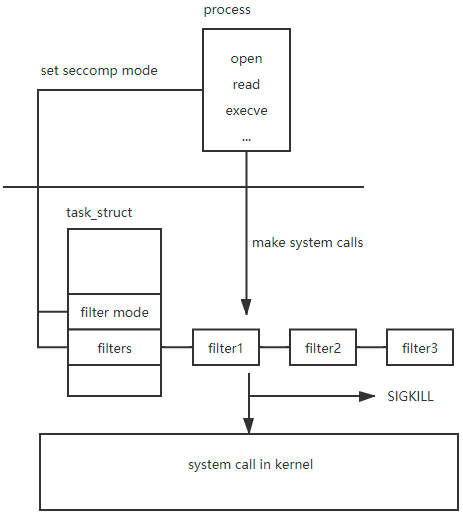
In the first part of this two-part blog series, we introduced seccomp. We covered its definition, how to configure it for processes, and the differences between strict and filter modes. Additionally, we explored how seccomp is implemented in the Linux kernel. Stay tuned for part two, where we’ll cover seccomp notifications. In that installment, we’ll illustrate how cloud technologies, such as container managers, utilize this mechanism to enhance container security.

A guest post by James Berthoty the founder of Latio Tech. The shift to cloud...

Read our update: Yet another reason why the xz backdoor is a sneaky b@$tard On...

Kubernetes 1.30 marks a significant milestone in the evolution of the widely used orchestration platform,...


 Continue as a guest
Continue as a guest